I’m a Data Scientist born from the Engineering world, so the only thing that outweighs my desire to make it work is to make it work right. To me, that means ensuring that data provides fair and accurate representation- not cutting corners just to find “an answer,” and that people fully understand the outcomes from sharing and using their data. Sometimes that means engaging my inner chemist and diving down to the fundamental mechanics of a problem. Sometimes it brings out the teammate in me to get everyone on the same page. Always, I get to learn something new. That last part is what got me into Data Science; the first part is what keeps me going.
On this site you’ll find recent samples from my portfolio, my resume, and a bit more about me.
Skills and Specialties

Featured Content
Panel: TechUp Women
Blog post about participating on the TechUp expert panel and mentoring a future technologist
WomenInTech
Read this post featured on TechUp
In January, 2020, I had the pleasure of participating in the final residential weekend of the TechUp program. The program gave me an opportunity to mentor a developing technologist in the final year of her biophysics PhD who is moving into data science. We worked together throughout the year combining her coursework from the TechUP curriculum with my experience of applied data science at Capital One to bridge the gap between academic projects and the workplace. We practiced breaking up big questions into smaller decisions and analyses to produce the best solution, collaborative development of a project on GitHub, modular package design, and unit testing. These skills were part of my learning curve over the past year, and they are critical for anyone who wants to hit the ground running- especially if they’re gaining business context as well.
Read Full Post
CodeAssist
Predict hospital billing codes using NLP on hospital notes
NLPIntroduction and Impact
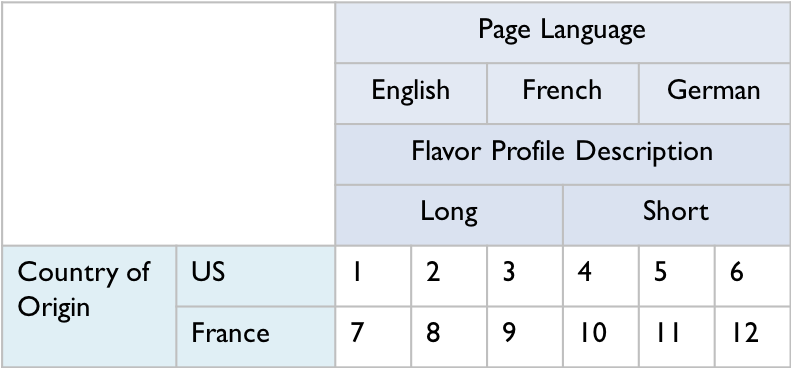
A key medical inefficiency is the hospital revenue cycle - where hospitals bill for services provided. Due to fragmented workflows, care providers must accurately bill for procedures that could have happened hours or days in the past1. Errors in the process are common and expensive - some sources suggest that up to 80% of billing cases contain an error in some form2, and errors often lead to billing discrepancies in excess of $13003. These errors also result in claims denials, which adversely affect the patient experience. CodeAssist is an intelligent system that leverages sophisticated machine learning techniques to generate surgical and anesthesia CPTs based on patient data, preoperative free text, and post-operative free text.
Working with industry professionals has led to a thorough understanding of the billing process, which is reflected in the product UX. Preoperative data informs an initial prediction, which is surfaced to the surgeon for confirmation or denial, along with a simple prompt for brief post-operative notes. The surgeon’s input is then passed to the facility billing staff along with a revised set of predictions and a risk rating of incorrect billing.

With a relatively small starting dataset, we predict anesthesia billing codes with 77.3% accuracy (human baseline of 72.9%). We predict incorrectly billed cases with 75% accuracy (baseline of 56%). Due to the large number of surgical CPT codes, human billing staff are still 11% more accurate in delineating exact sets of surgical CPT codes, which we aim to address with ongoing data collection efforts.
Read Full Post
Vous voulez du vin?
Experimental analysis of wine-market features and purchase likelihood
Market TestingSummary
Design, launch, and statistical analysis of a multifactorial advertising experiment to evaluate the impact of foreign language marketing on perceived value of wine. Analysis used experimental techniques and multiple types of linear regression models.
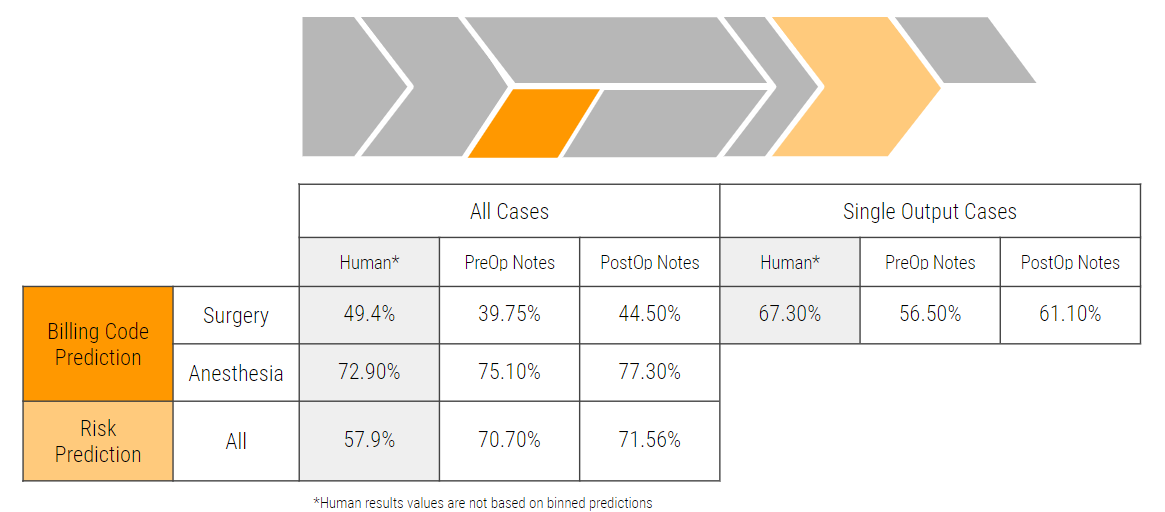
Design
This experiment was used to analyze multiple effects of marketing environment on the perception of product value. The multifactorial design includes three treatment variables: page language, flavor description length, and country of origin. While a product’s country of origin is non-mutable for marketing purposes, this was an important feature to analyze any interaction with the page format. In addition to French and English, German was added as a language format to observe the effects of a foreign language that’s not usually associated with the product. The description length was be used both as a feature and a metric of dosage for the language format.