CodeAssist
Introduction and Impact
A key medical inefficiency is the hospital revenue cycle - where hospitals bill for services provided. Due to fragmented workflows, care providers must accurately bill for procedures that could have happened hours or days in the past1. Errors in the process are common and expensive - some sources suggest that up to 80% of billing cases contain an error in some form2, and errors often lead to billing discrepancies in excess of $13003. These errors also result in claims denials, which adversely affect the patient experience. CodeAssist is an intelligent system that leverages sophisticated machine learning techniques to generate surgical and anesthesia CPTs based on patient data, preoperative free text, and post-operative free text.
Working with industry professionals has led to a thorough understanding of the billing process, which is reflected in the product UX. Preoperative data informs an initial prediction, which is surfaced to the surgeon for confirmation or denial, along with a simple prompt for brief post-operative notes. The surgeon’s input is then passed to the facility billing staff along with a revised set of predictions and a risk rating of incorrect billing.

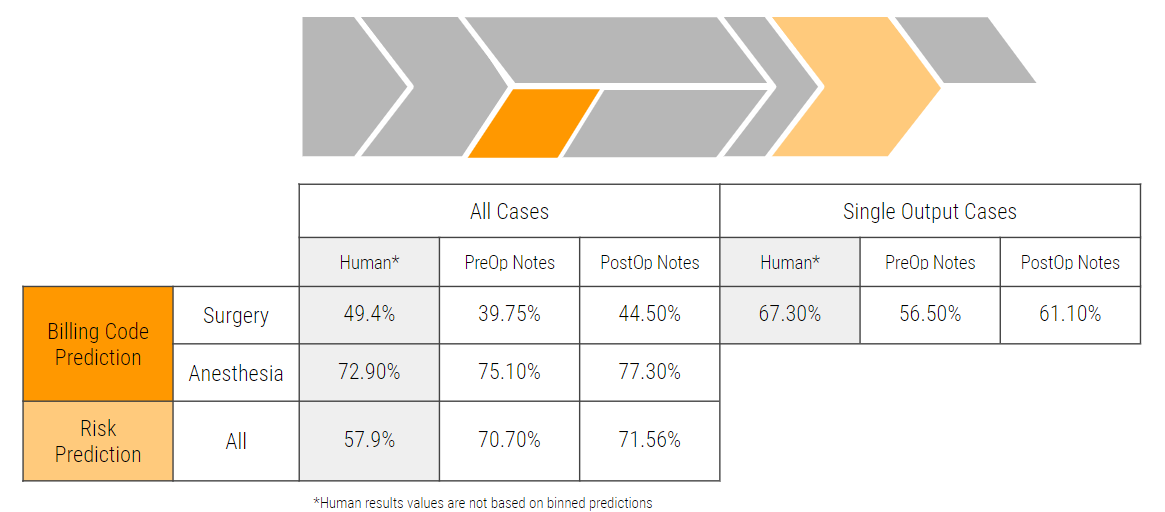
With a relatively small starting dataset, we predict anesthesia billing codes with 77.3% accuracy (human baseline of 72.9%). We predict incorrectly billed cases with 75% accuracy (baseline of 56%). Due to the large number of surgical CPT codes, human billing staff are still 11% more accurate in delineating exact sets of surgical CPT codes, which we aim to address with ongoing data collection efforts.
Pre-Model Processing
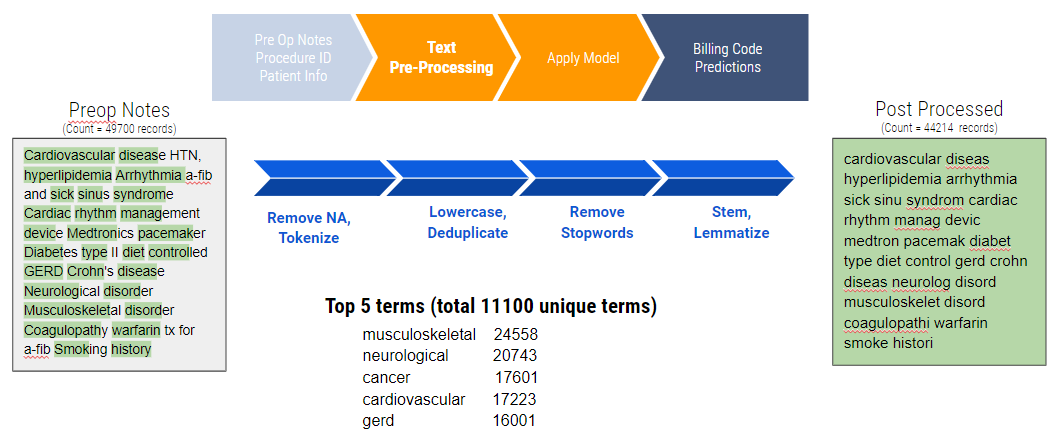
In order to ensure the most efficient model, CodeAssist employed two major data preprocessing steps: text cleaning and output class category merging or binning.
Text cleaning included null/NA data removal, tokenization, lowercasing, deduplication, stopword removal, stemming and lemmatization on the input, namely, the preoperative notes, used to train the model.
The motivation for binning was driven by the observation that the number of output classes was very large in comparison to the size of the dataset, and that there were many clusters of output codes referring to surgical procedures that differed only in details of dimensions, location or other attribute. Predicting the specific code based on preoperative notes alone would have led to inaccuracies, since in many cases the specific dimensions and locations of the procedure are only known after the procedure is complete.
From a performance metric perspective, by combining these codes into bins, training the models on the bins and predicting the bins, CodeAssist achieved a higher accuracy and recall, as more false positives were surfaced when the bin(s) are expanded and presented to the user. This issue is mitigated because the surgeon can select the correct individual codes from the expanded bin(s).
The decision to prioritize accuracy and recall over precision was validated with potential users of the system.
CodeAssist Code Prediction
CodeAssist leverages a unique design to address the key challenges of predicting surgical CPT codes. The model architecture allows for the consumption of multi-label training data and yields multiple outputs using proprietary heuristic confidence thresholds.
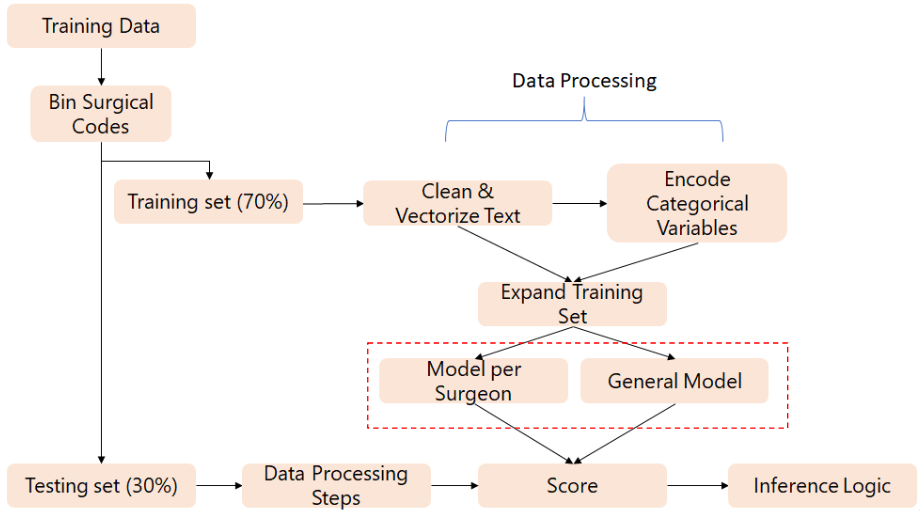
The ML pipeline contains both a surgeon-specific model set as well as a general model set. The surgeon specific model set captures the tendencies of high-volume surgeons, while the general model prevents bias against new codes. Combining predictions from both model sets allows for robust, specific, and generalizable predictions.
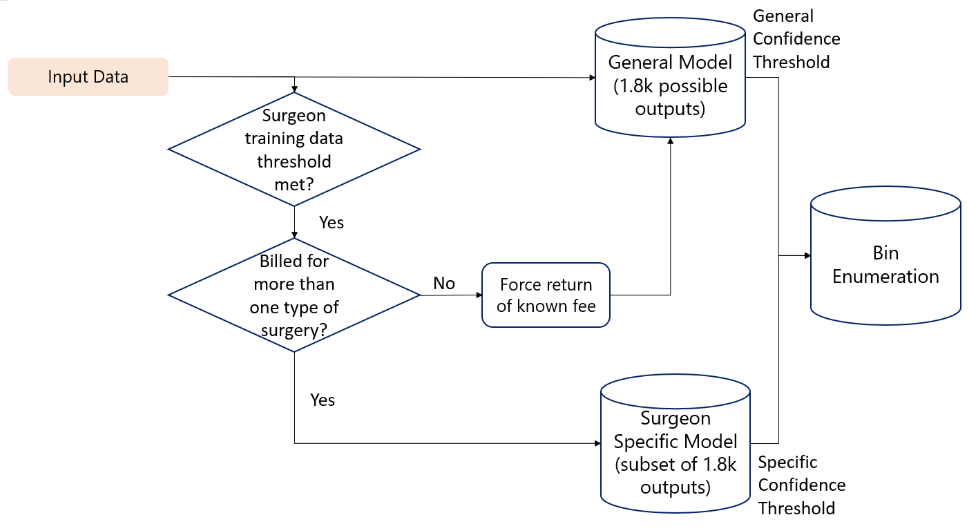
This video explains our training paradigm and inference logic and how it impacts code predictions.
CodeAssist Risk Prediction
In addition to predicting CPT codes, CodeAssist also predicts the risk of a billing error by a facility. The predictor is built upon a CNN (Convolutional Neural Network) based text classifier: the model uses the Pre-Op and Post-Op notes as its input and predicts the accuracy of a facility billing coder by assessing the depth of information in the provided text.
To capture the semantic meanings of words, we encode the input text using pre-trained GloVe word embeddings. These word embeddings are not rigidly implanted- they can be altered during the training of the model, enabling the learning of task-specific features. To alleviate overfitting, we also apply L2 regularization and dropout to the model, making each decision node more robust.
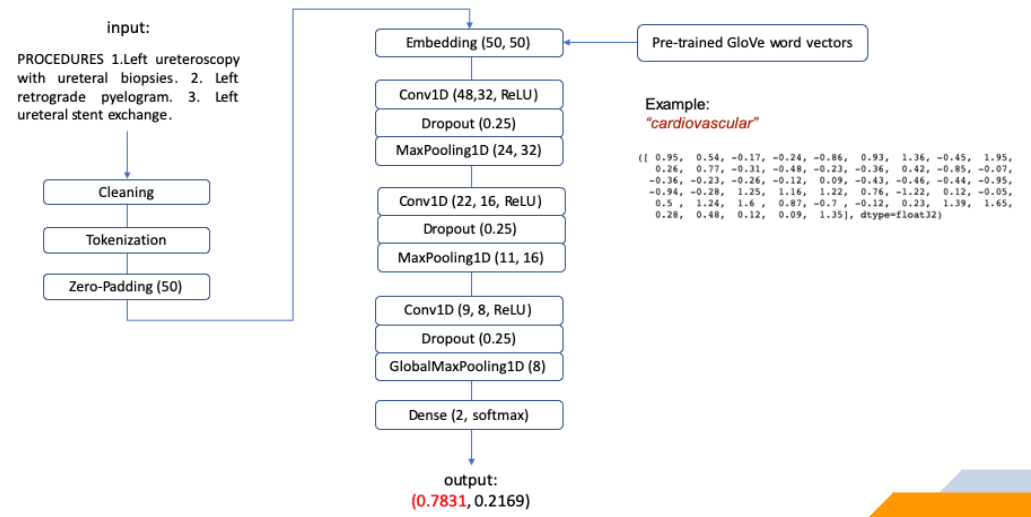
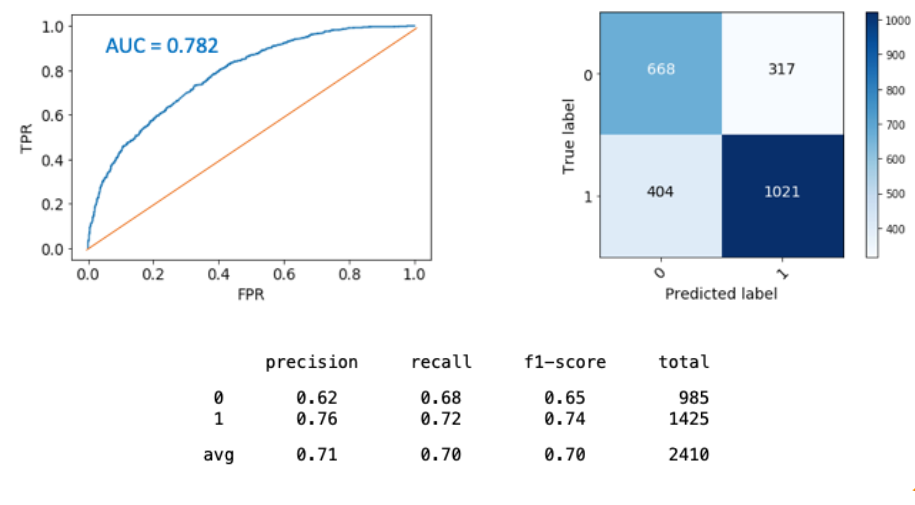
Our EDA shows the hospital billing codes are correct 57% of the time. Improving over this baseline, our CNN model has achieved a risk prediction accuracy of 70% across patients. Experiments show the prediction accuracy improves with the size of training data, thus, we expect better model performance when more data becomes available.
{kind=link}
{kind=link}
Demo
CodeAssist Code Prediction
_
CodeAssist Risk Prediction
Team
